Navigating the Landscape: A Comprehensive Examination of Hashmaps and Maps in Data Structures
Related Articles: Navigating the Landscape: A Comprehensive Examination of Hashmaps and Maps in Data Structures
Introduction
With great pleasure, we will explore the intriguing topic related to Navigating the Landscape: A Comprehensive Examination of Hashmaps and Maps in Data Structures. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
Navigating the Landscape: A Comprehensive Examination of Hashmaps and Maps in Data Structures
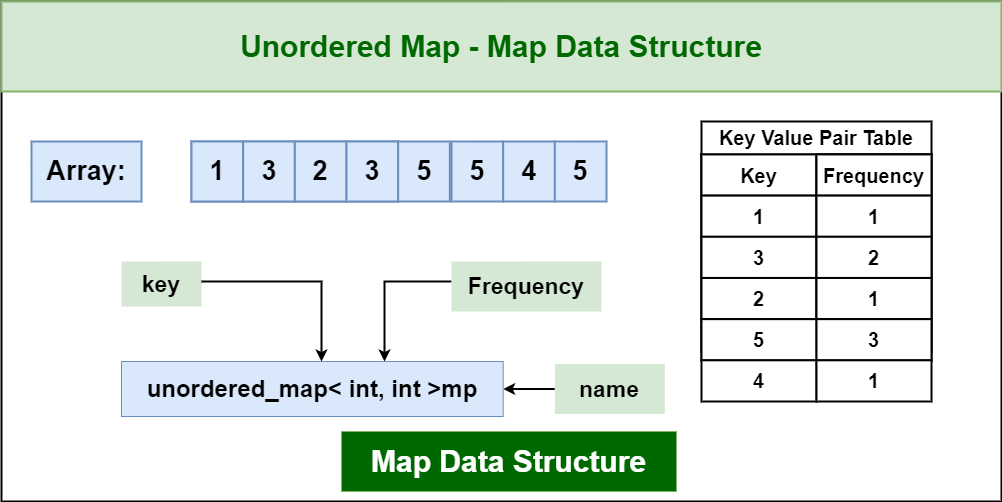
In the realm of computer science, data structures serve as the building blocks for efficient data management and manipulation. Among these structures, hashmaps and maps stand out as powerful tools for storing and retrieving data based on key-value pairs. While both share the fundamental principle of associating keys with values, they diverge in their underlying implementation and performance characteristics. This article delves into the intricacies of hashmaps and maps, providing a comprehensive understanding of their similarities, differences, and practical implications.
Understanding the Fundamentals: Key-Value Pairs and Data Retrieval
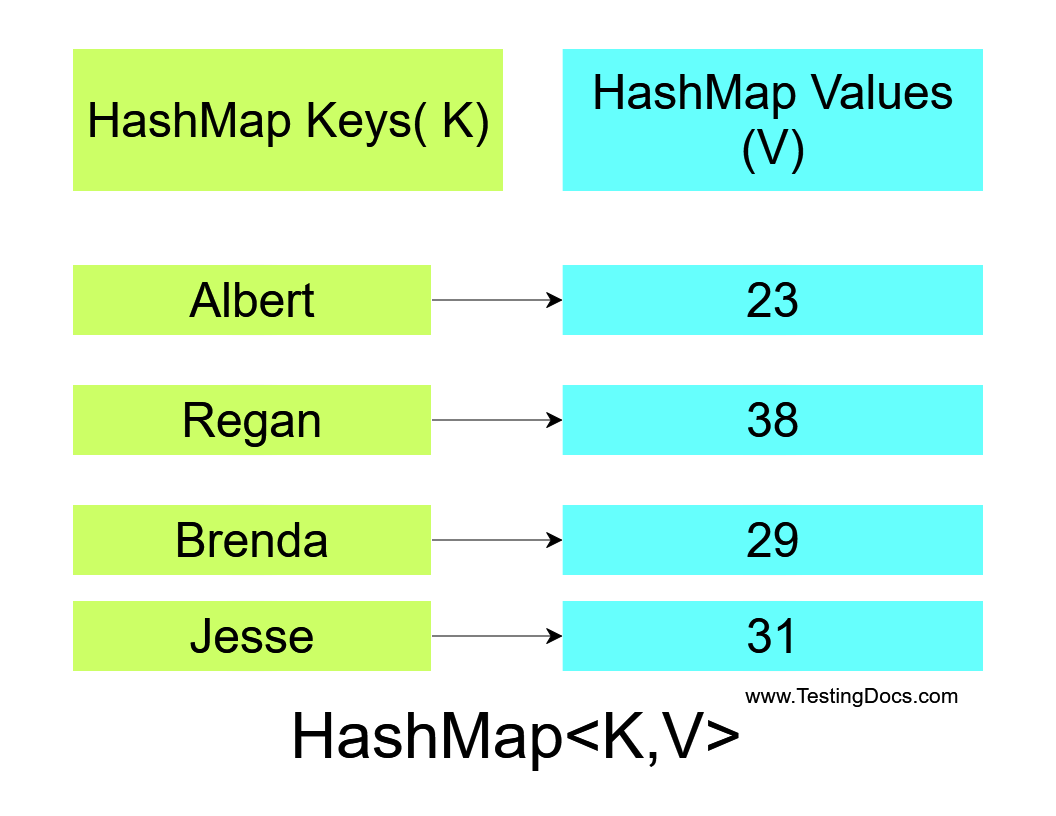
At their core, both hashmaps and maps are designed to store and retrieve data based on a unique key. This key acts as a reference point, allowing the retrieval of its corresponding value. For instance, imagine a phonebook where each person’s name (the key) is associated with their phone number (the value). This fundamental concept of key-value pairs forms the bedrock of both hashmaps and maps.
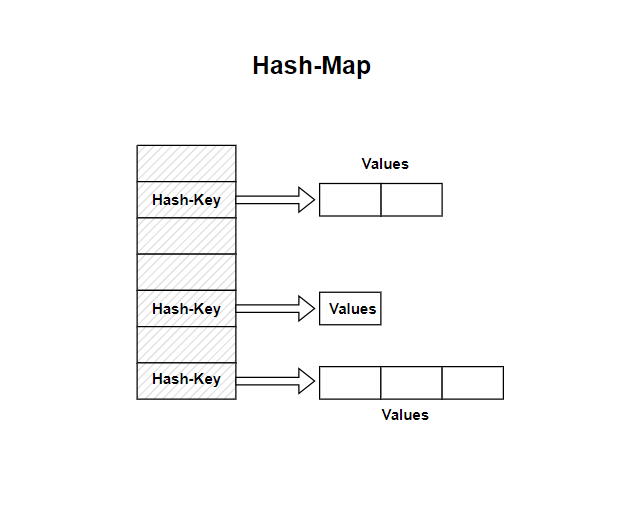
The Hashmap: Leveraging Hash Functions for Efficient Access
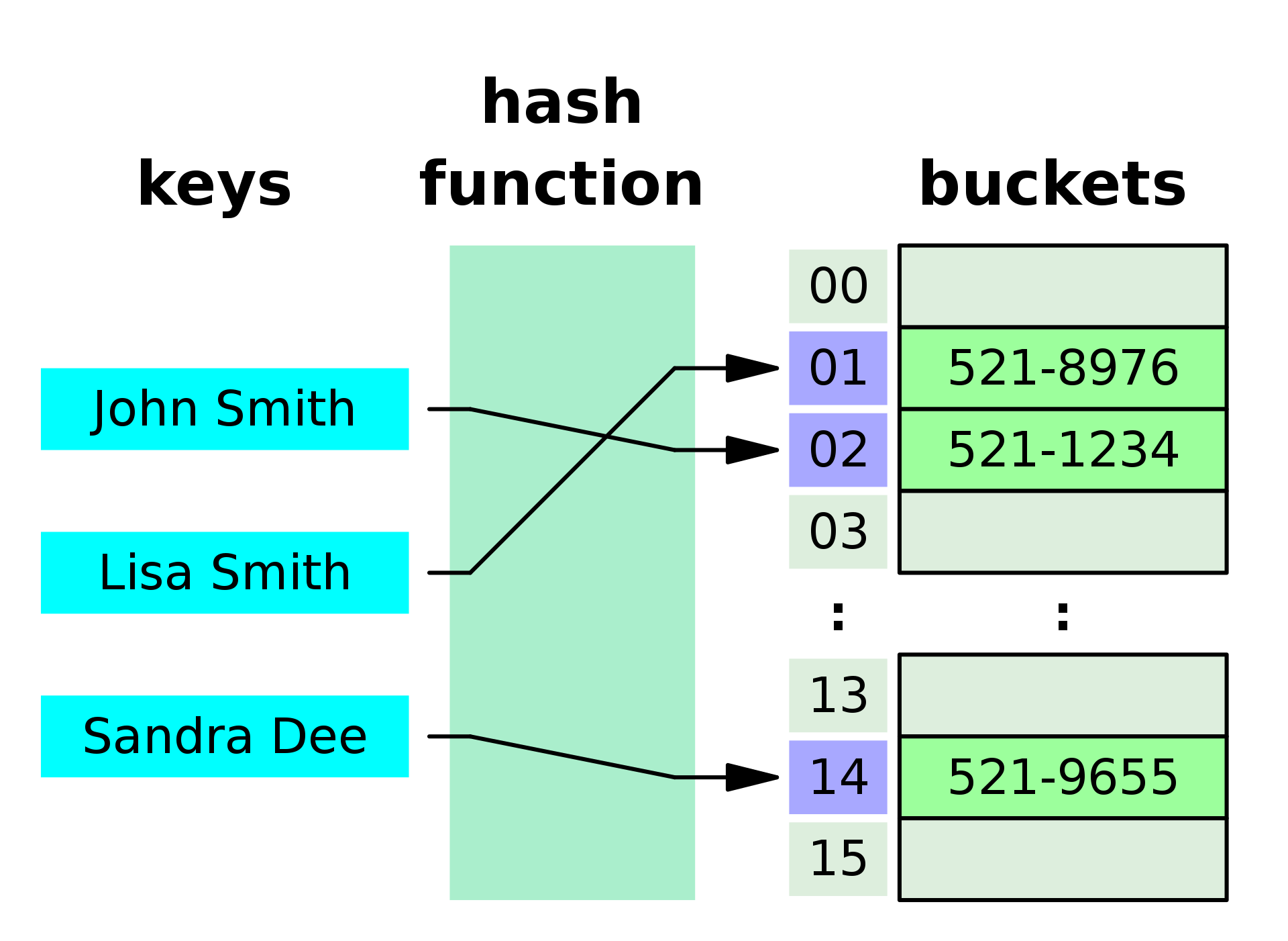
A hashmap, also known as a hash table, utilizes a hash function to determine the location of a key-value pair within its underlying storage. The hash function takes the key as input and generates a unique hash value, which is then used to index the corresponding data. This approach enables remarkably fast access to elements, making hashmaps ideal for scenarios where frequent lookups are required.
How Hashmaps Work: A Step-by-Step Illustration
- Hash Function Application: When a key-value pair is inserted into a hashmap, the hash function calculates a hash value based on the key.
- Mapping to an Index: This hash value is then used to map the key-value pair to a specific index within the hashmap’s underlying storage structure, typically an array.
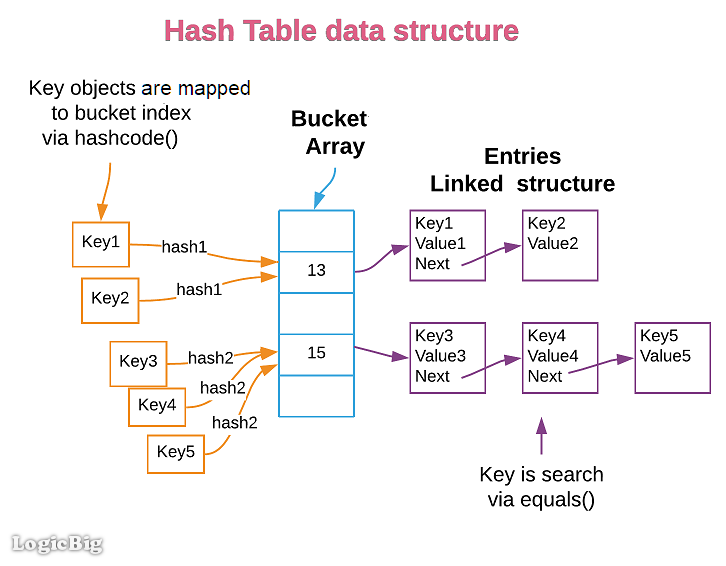
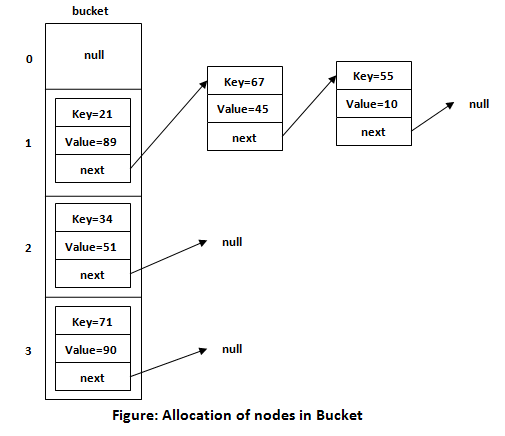
- Collision Handling: If multiple keys generate the same hash value, a collision occurs. Various techniques, such as separate chaining or open addressing, are employed to resolve these collisions and ensure efficient data retrieval.
- Retrieving Data: To retrieve a value associated with a key, the same hash function is applied to the key, generating the corresponding index. From this index, the associated value is retrieved.
The Map: A Versatile Data Structure with Ordered Keys
In contrast to hashmaps, maps do not rely on hash functions. Instead, they maintain an internal ordering of keys, typically employing tree-based structures such as red-black trees or binary search trees. This ordering allows for efficient iteration through the keys and provides the ability to perform operations like finding the minimum or maximum key.
Map Implementation and Key Ordering:
- Tree-Based Structure: Maps typically utilize tree-based structures to store key-value pairs, where keys are arranged in a hierarchical order.
- Key Ordering: This ordering allows for efficient navigation through the keys, facilitating operations like finding the smallest or largest key.
- Balanced Trees: To maintain performance, maps often employ balanced trees, such as red-black trees, which ensure that the height of the tree remains relatively balanced, preventing worst-case scenarios where search operations become inefficient.
Hashmaps vs Maps: A Comparative Analysis
| Feature | Hashmap | Map |
|---|---|---|
| Key Ordering | Unordered | Ordered |
| Data Retrieval | Fast, constant time (O(1) on average) | Logarithmic time (O(log n)) |
| Insertion/Deletion | Fast, constant time (O(1) on average) | Logarithmic time (O(log n)) |
| Iteration | Not directly supported | Supported, in order of keys |
| Space Complexity | Fixed, typically an array | Dynamic, based on tree structure |
| Collision Handling | Required, impacts performance | Not applicable |
| Use Cases | Frequent lookups, large datasets | Ordered key access, balanced performance |
Hashmaps: The Power of Speed and Efficiency
Hashmaps excel in scenarios where rapid data retrieval is paramount. Their constant-time average access makes them ideal for applications such as:
- Caching: Storing frequently accessed data for quick retrieval.
- Databases: Indexing and retrieving data based on unique keys.
- Hash-Based Algorithms: Implementing algorithms that rely on hash functions for efficient data processing.
- Symbol Tables: Mapping symbols to their corresponding values in programming languages.
Maps: Maintaining Order and Flexibility
Maps offer a balance between speed and the ability to maintain key ordering. They are well-suited for applications where:
- Ordered Access: Data needs to be accessed in a specific order, such as sorted lists or ordered sets.
- Range Queries: Searching for values within a specific range of keys.
- Tree-Based Operations: Utilizing tree-based algorithms for efficient data processing.
- Key-Value Pairs with Ordering: Representing data where the order of keys is significant.
Beyond the Basics: Exploring Key Concepts and Advanced Features
1. Collision Handling in Hashmaps
Collision handling is a critical aspect of hashmap performance. When two keys generate the same hash value, a collision occurs. Effective collision handling techniques are essential to prevent performance degradation. Common approaches include:
- Separate Chaining: Each index in the hashmap’s array points to a linked list, where colliding key-value pairs are stored. This allows for efficient insertion and retrieval, as the linked list can grow dynamically.
- Open Addressing: When a collision occurs, the hashmap probes for an empty slot in the array, potentially using linear probing, quadratic probing, or double hashing techniques.
2. Map Implementations and Trade-offs
The choice of tree-based structure for map implementations influences performance characteristics.
- Red-Black Trees: Offer a balance between search efficiency and insertion/deletion speed, making them a popular choice for general-purpose maps.
- AVL Trees: Provide strict balance, guaranteeing logarithmic search time but potentially sacrificing insertion/deletion performance.
- B-Trees: Designed for large datasets and disk-based storage, offering efficient access to data stored on secondary storage.
3. Hash Function Selection and Performance
The choice of hash function is crucial for hashmap performance. A well-designed hash function should:
- Distribute Keys Evenly: Minimize collisions by mapping keys to different hash values.
- Be Fast to Compute: Efficiently calculate hash values for quick access.
- Avoid Clustering: Prevent keys from clustering together, leading to performance degradation.
4. Dynamic Resizing in Hashmaps
As data is inserted into a hashmap, its capacity may need to be increased to maintain efficient performance. Dynamic resizing involves allocating a larger array and rehashing existing data, ensuring that the load factor (ratio of elements to capacity) remains within a reasonable range.
5. Map Iterators and Key-Value Pairs
Maps provide iterators that allow for sequential access to key-value pairs. This enables efficient traversal through the map’s contents, providing a mechanism for processing data in a specific order.
FAQs: Addressing Common Queries about Hashmaps and Maps
Q1: When should I use a hashmap over a map?
A1: Choose a hashmap when rapid data retrieval and unordered access are paramount. Hashmaps excel in scenarios where frequent lookups are required, such as caching, database indexing, and symbol tables.
Q2: When should I use a map over a hashmap?
A2: Opt for a map when ordered access to keys is crucial. Maps are suitable for applications where data needs to be processed in a specific order, such as sorted lists, range queries, and tree-based algorithms.
Q3: Are hashmaps always faster than maps?
A3: Hashmaps offer constant-time average access, making them faster for typical lookups. However, in worst-case scenarios where collisions occur frequently, their performance can degrade. Maps, with their logarithmic time access, provide more consistent performance.
Q4: What are the trade-offs between hashmaps and maps?
A4: Hashmaps prioritize speed and efficiency for unordered access, while maps offer ordered access and more consistent performance, but with a slight performance penalty. The choice depends on the specific requirements of the application.
Q5: How do I choose the right hash function for a hashmap?
A5: Select a hash function that distributes keys evenly, is fast to compute, and avoids clustering. Common techniques include modulo operation, multiplicative hashing, and cryptographic hash functions.
Q6: What are the common implementations of maps?
A6: Maps are typically implemented using tree-based structures, such as red-black trees, AVL trees, and B-trees. The choice depends on factors such as data size, balance requirements, and storage medium.
Tips: Optimizing Performance and Choosing the Right Data Structure
- Choose the Right Data Structure: Carefully consider the requirements of your application. If rapid unordered access is paramount, use a hashmap. If ordered access and balanced performance are needed, opt for a map.
- Handle Collisions Effectively: In hashmaps, implement efficient collision handling techniques, such as separate chaining or open addressing, to minimize performance degradation.
- Select a Suitable Hash Function: Choose a hash function that distributes keys evenly, is fast to compute, and avoids clustering.
- Optimize for Specific Use Cases: Tailor your data structure implementation to the specific needs of your application. For example, if you are dealing with a large dataset, consider using a B-tree for efficient disk-based storage.
- Benchmark and Profile: Measure the performance of your data structures and identify potential bottlenecks. Optimize your implementation based on the results.
Conclusion: Empowering Data Management through Efficient Structures
Hashmaps and maps provide powerful tools for managing key-value pairs, each offering distinct advantages and trade-offs. Hashmaps excel in scenarios where rapid unordered access is paramount, while maps provide ordered access and more consistent performance. By understanding their strengths and weaknesses, developers can choose the appropriate data structure to optimize performance and efficiency in their applications. Ultimately, selecting the right data structure is a crucial step in building robust, scalable, and efficient software systems.



Closure
Thus, we hope this article has provided valuable insights into Navigating the Landscape: A Comprehensive Examination of Hashmaps and Maps in Data Structures. We appreciate your attention to our article. See you in our next article!