Navigating the Landscape: Maps and Hashmaps in Data Structures
Related Articles: Navigating the Landscape: Maps and Hashmaps in Data Structures
Introduction
With great pleasure, we will explore the intriguing topic related to Navigating the Landscape: Maps and Hashmaps in Data Structures. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
Navigating the Landscape: Maps and Hashmaps in Data Structures
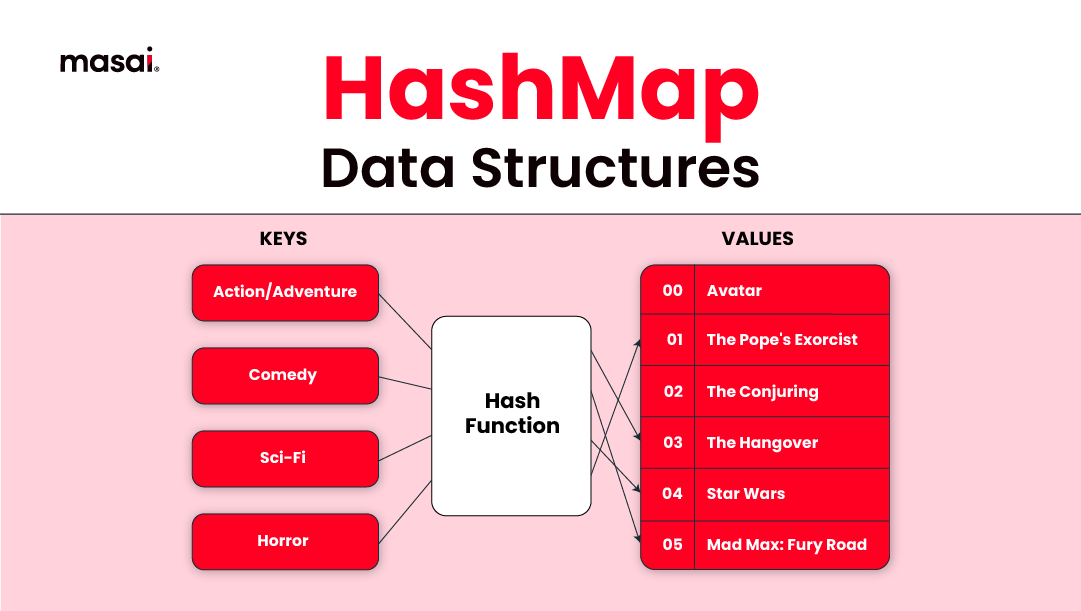
In the realm of data structures, the ability to store and retrieve information efficiently is paramount. Maps and hashmaps, both powerful tools for organizing key-value pairs, offer distinct advantages and trade-offs, making them invaluable for various programming tasks. Understanding their nuances and applications is crucial for developers seeking optimal performance and clarity in their code.
Understanding Maps: A Foundation for Key-Value Storage
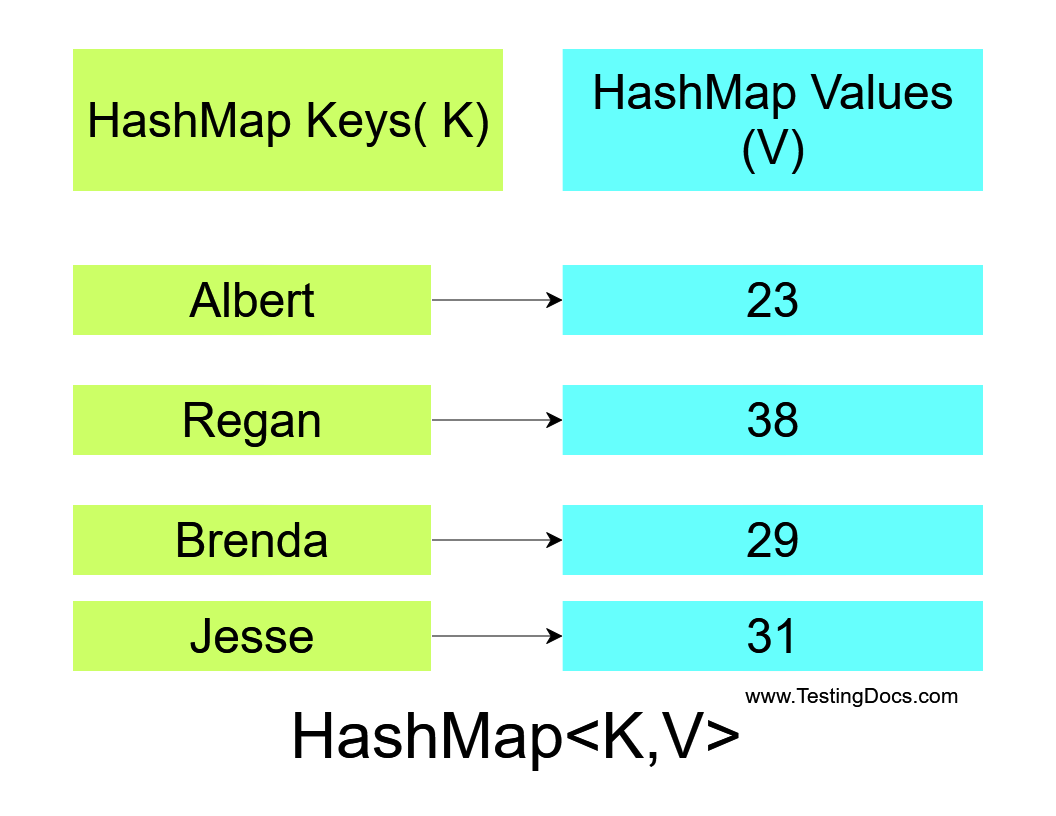
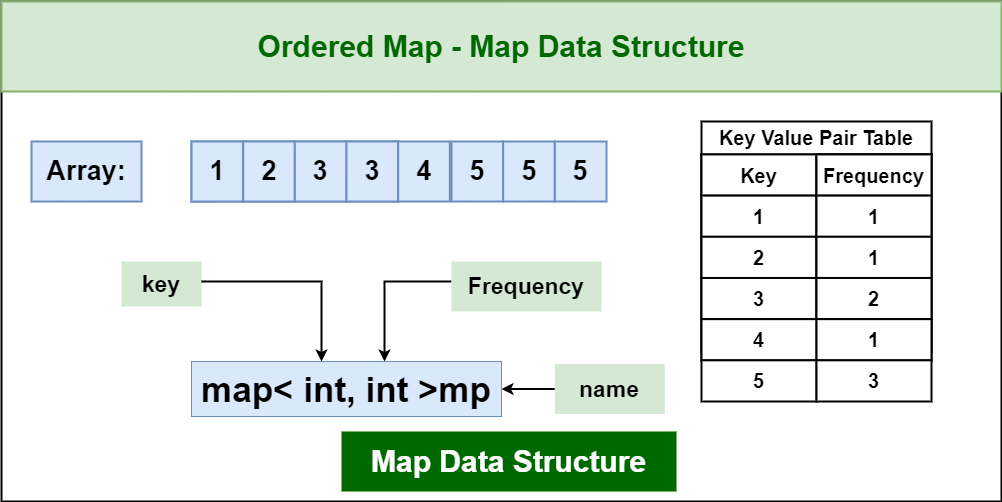
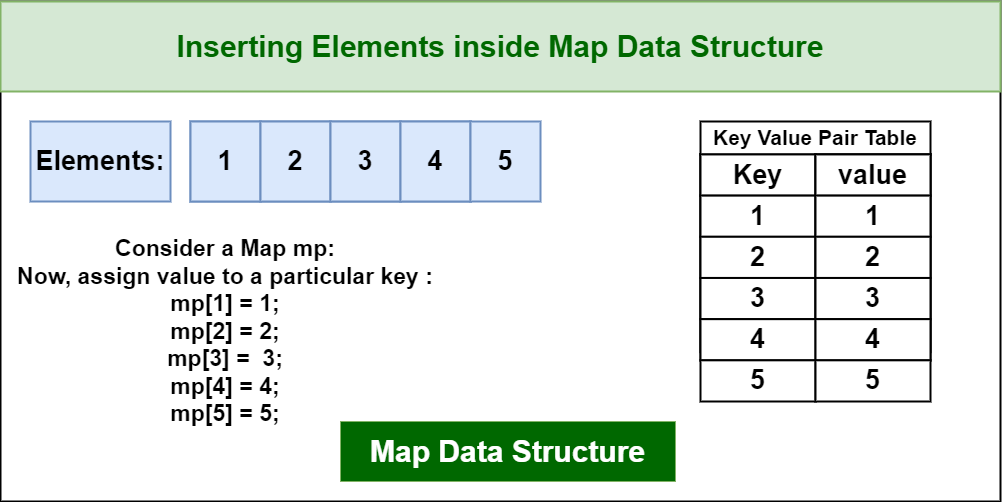
Maps, often referred to as dictionaries or associative arrays, are abstract data structures that associate keys with corresponding values. This fundamental concept allows for efficient retrieval of values based on their unique keys. Conceptually, maps resemble a physical dictionary where each word (key) leads to its definition (value).
Key Features of Maps:
- Key-Value Pairs: Maps store data as pairs, linking keys to their associated values.
- Unique Keys: Each key within a map must be unique, ensuring a one-to-one relationship between keys and values.
- Efficient Lookup: Maps provide fast access to values based on their corresponding keys.
- Dynamic Size: Maps can dynamically adjust their size to accommodate new key-value pairs.
Implementation Variations: Navigating the Map Landscape
While the underlying principle of maps remains consistent, their implementation can vary significantly across different programming languages. Common implementations include:
- Binary Search Trees (BSTs): BSTs utilize a hierarchical structure where keys are arranged in a specific order. This structure allows for efficient searching and insertion operations, particularly for sorted data.
- Hash Tables: Hash tables employ a hashing function to map keys to specific locations within an array, enabling rapid lookup and insertion.
- Balanced Trees: To address potential performance issues associated with unbalanced BSTs, balanced tree structures like AVL trees and red-black trees maintain a balanced structure, guaranteeing efficient search and insertion operations.
Delving into Hashmaps: Efficiency Through Hashing
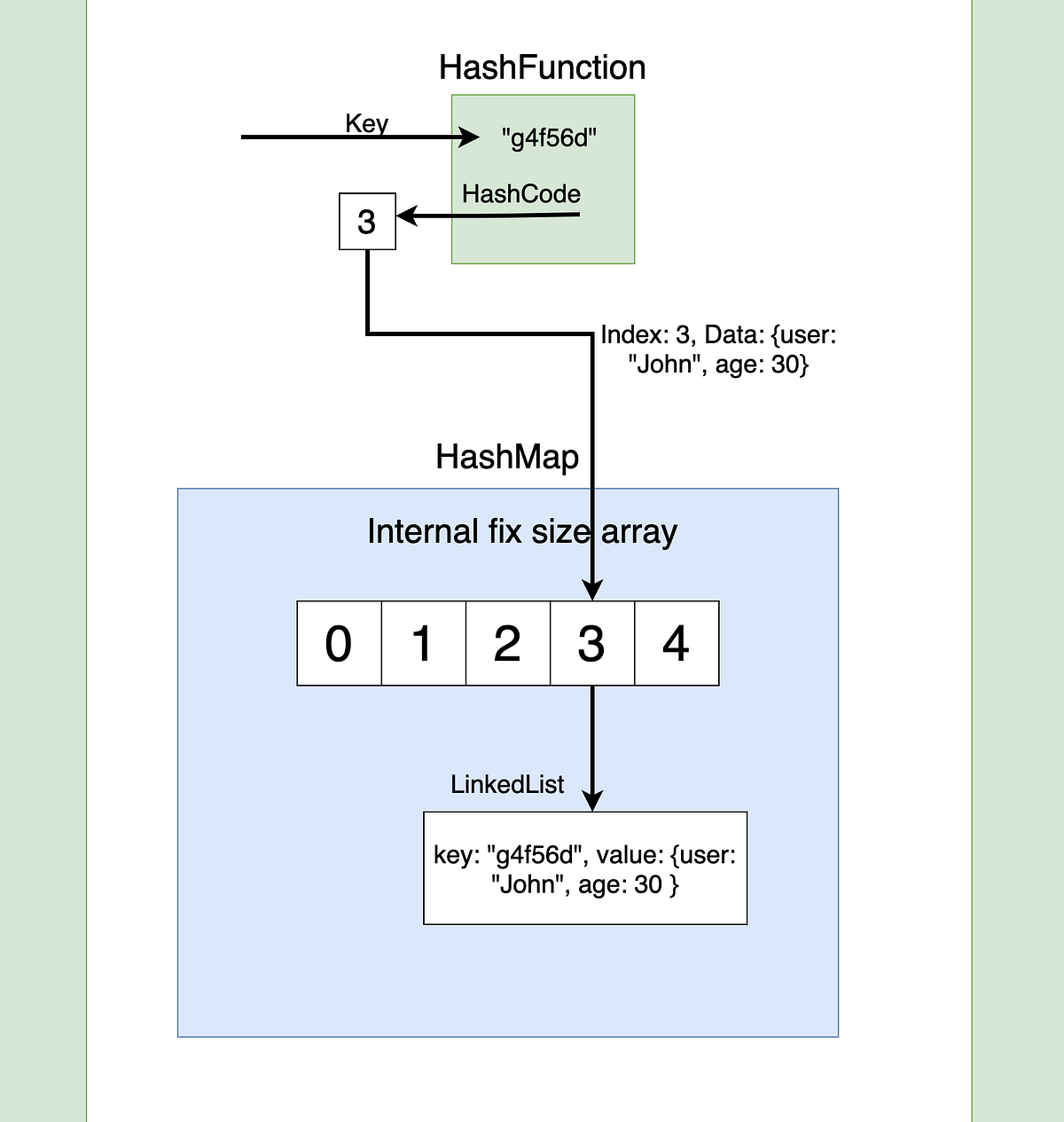
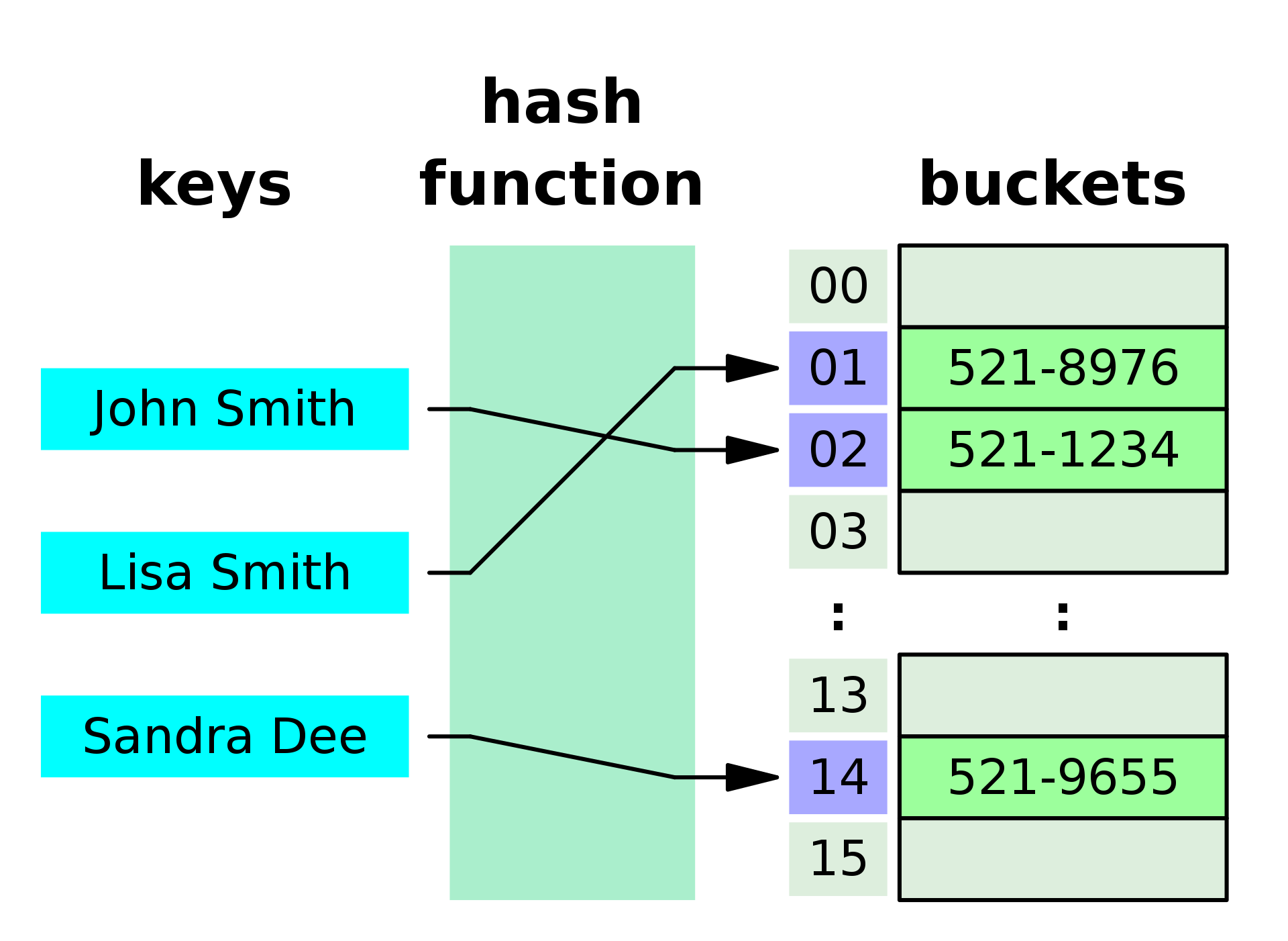
Hashmaps, a specific implementation of maps, leverage hashing techniques for efficient key-value storage and retrieval. They utilize a hash function to convert keys into unique indices within an array, enabling near-constant time access to values. This makes hashmaps particularly advantageous for applications requiring rapid lookup operations.
Key Features of Hashmaps:
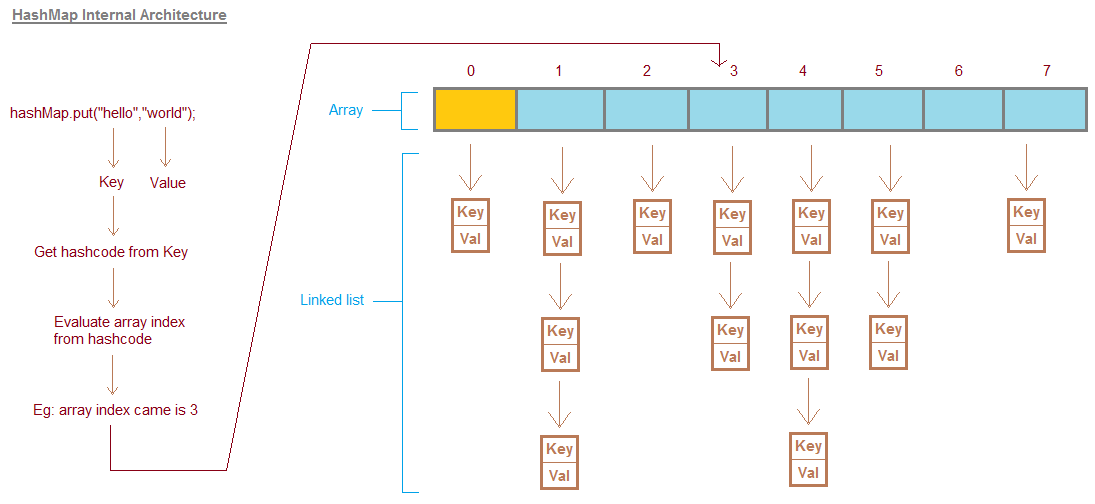
- Hash Function: Hashmaps rely on a hash function to map keys to unique indices within an array.
- Collision Handling: When multiple keys map to the same index (collision), hashmaps employ various strategies like chaining or open addressing to resolve these conflicts.
- Average Constant Time Operations: Hashmaps typically provide near-constant time complexity for insertion, deletion, and retrieval operations, making them highly efficient for large datasets.
Choosing the Right Tool: Map vs. Hashmap
The choice between maps and hashmaps often boils down to the specific requirements of the task at hand. Here’s a breakdown of their respective strengths and weaknesses:
Maps:
-
Strengths:
- Ordered Retrieval: Some implementations of maps maintain the order of insertion, allowing for predictable iteration.
- Flexibility: Maps provide a general framework for key-value storage, allowing for various implementations based on specific needs.
-
Weaknesses:
- Potential Performance Issues: Depending on the implementation, map operations can have varying time complexities, potentially leading to performance bottlenecks.
- Limited Applications: Maps might not be the most efficient choice for scenarios requiring extremely fast lookup operations.
Hashmaps:
-
Strengths:
- High Performance: Hashmaps offer near-constant time complexity for most operations, making them ideal for applications demanding speed.
- Scalability: Hashmaps can handle large datasets efficiently, making them suitable for scenarios involving a high volume of data.
-
Weaknesses:
- Unordered Retrieval: Hashmaps generally do not maintain the order of insertion, making it challenging to iterate over elements in a specific sequence.
- Collision Handling: Efficient collision handling is crucial for maintaining hashmap performance. Poorly designed hash functions or excessive collisions can significantly impact performance.
Frequently Asked Questions (FAQs) about Maps and Hashmaps:
Q: What are the key differences between maps and hashmaps?
A: Maps are abstract data structures that store key-value pairs, while hashmaps are a specific implementation of maps that leverage hashing techniques for efficient storage and retrieval.
Q: When should I use a map over a hashmap?
A: Use a map when order of insertion is important, or when flexibility in implementation is required.
Q: When should I use a hashmap over a map?
A: Use a hashmap when fast lookup operations are paramount and order of insertion is not critical.
Q: Are hashmaps always faster than maps?
A: While hashmaps generally offer faster performance, the actual speed can vary depending on factors like the quality of the hash function and the occurrence of collisions.
Q: How do I handle collisions in hashmaps?
A: Collision handling strategies include chaining (linking values with the same index) and open addressing (finding alternative indices).
Tips for Effective Use of Maps and Hashmaps:
- Choose the Right Implementation: Select the most appropriate map implementation based on your specific needs, considering factors like order of insertion, performance requirements, and data size.
- Optimize Hash Functions: For hashmaps, use high-quality hash functions to minimize collisions and ensure efficient performance.
- Handle Collisions Effectively: Implement robust collision handling mechanisms to mitigate performance degradation caused by collisions.
- Consider Data Distribution: Analyze the distribution of keys to ensure the chosen hash function effectively distributes them across the hash table.
Conclusion: Embracing the Power of Maps and Hashmaps
Maps and hashmaps provide powerful tools for organizing and accessing data efficiently. Understanding their strengths, weaknesses, and implementation nuances empowers developers to choose the most suitable data structure for their specific needs. By carefully considering factors like performance, data distribution, and order requirements, developers can leverage these data structures to build robust and efficient applications. Whether navigating a complex dictionary or storing a vast database of information, maps and hashmaps remain essential building blocks in the world of data structures.


Closure
Thus, we hope this article has provided valuable insights into Navigating the Landscape: Maps and Hashmaps in Data Structures. We appreciate your attention to our article. See you in our next article!